Introduction
This is a list of my projects. Some of these are stable and released, others are in-progress, and some exist only as a concept at this point. Every project I work on is permissively licensed (using the MIT License, because that one gives the most freedom to users of the code.
I believe that writing software is a creative endeavour, and as such I like to explore and build different things that interest me. Doing so in the open allows others to take inspiration and learn from them, and sometimes help me make them better.
Overview
Here is an overview of my personal projects, ranked by priority (highest first). The colors indicate readiness of the project overall and the individual features that I am working on.

Passgen
Passphrase generator that can generate arbitrary sequences from a dialect of regular expressions. It has some features for generating high-entropy memorable passphrases, such as using wordlists or generating pronounceable words from wordlists using a markov-chain monte-carlo method.
The purpose of Passgen is threefold:
- to make it easy to generate secure passphrases
- to make it easy to generate passphrases that are memorable
- to be able to accurately calculate the entropy of calculated passphrases
You can think of Passgen as evaluating regular expressions in reverse, randomly choosing anytime there are multiple options. It has some additional syntax elements (that are discussed below) for the additional features it has, such as being able to pick random words from wordlists.
Examples
Some examples of using Passgen on the command-line. Unless you use the master-passphrase mode, every run of Passgen will yield a different, random output.
Generate arbitrary randomized passphrases from a format string. In this example, we are randomly generating sixty-four alphanumerical characters.
$ passgen '[a-zA-Z0-9]{64}'
wy08qpQHaO7jTANOwfP55W404Gkh9rjktMBCBAcKfokG0k4aoG9nmyX68pOWR0j6
Choose random words from a wordlist for XKCD-style passphrases. To use a wordlist,
we first need to tell Passgen where to find it (the -w flag), and then we can
reference it in the pattern using the \w{name} notation. Passgen will choose
a random word from the list.
$ passgen -w english:/usr/share/dict/words '\w{english}(-\w{english}){3}[0-9]{2,4}'
condolences-permits-oriental's-wavy67
Use a markov-chain to generate high-entropy pronounceable words. Similar to using the wordlist mode, we need to declare the word list. However, the markov-chain mode uses the letter distribution of the wordlist to generate pseudo-words rather than picking words. This results in a higher entropy, but still generates words that are pronounceable (and therefore memorable).
$ passgen -w english:/usr/share/dict/words '\m{english}(-\m{english}){3}'
una-chs-Wated-bradechughtembing
Calculates the entropy for every generated passphrase. The entropy measures how much randomness went into creating the passphrase, and therefore the amount of work an attacker would have to do to guess it. Incrementing the entropy by one doubles the amount of work necessary.
$ passgen -e -p apple2
entropy: 107.18 bits
j5KQqM-kWBomL-R6XoO9
Can define presets for commonly used passphrase patterns. Passgen comes with a set of predefined presets, but you can also configure your own in a configuration file.
$ passgen -p apple2
2k3zkR-M2h3YE-0E05Jw
Using the master-passphrase mode, it will generate deterministic passphrases for different domain-account pairs. As long as you remember the master passphrase, you can always regenerate the passphrase. This allows you to use Passgen as a kind of password manager.
$ passgen -m mysecurepass -d google.com
HpkoED-H8qanE-GWM1Mp
Syntax
The following table is a syntax overview for the Passgen pattern description
language. An underscore (_) represents any valid syntax element (or, in the
case of a group, any sequence of valid syntax elements).
| Name | Examples | Description |
|---|---|---|
| Literal | abc | Emitted unchanged |
| Set | [abc],[a-zA-Z0-9] | Consists of a list of character or character ranges (separated by -). Randomly chooses a single character from the set. Characters from the set are weighted, if a character appears multiple times it is more likely to be picked. |
| Wordlist | \w{english} | Emits random word from the wordlist named english. |
| Markov | \m{english} | Emits random markov-chain generated word from the wordlist named english. |
| Preset | \p{name} | Evaluates the preset name and emits its output. |
| Group | (_|_) | Consists of segments of syntax elements separated by pipe (|) characters. Randomly chooses one of the segments and emits their output. |
| Optional | _? | Randomly decides to emit the element. Can be placed after any syntax element. Use a group to apply it to multiple elements. |
| Repeat | _{64}_{32,48} | Repeat the preceding element n times. If a range of lengths is specified, choose a random value within the range. |
Implementations
Initially, Passgen was implemented as a C project that evolved over time. The current implementation is written in Rust, contains less code and is faster than the legacy C implementation.
- Rust implementation
- C implementation
- Web application
- Desktop application (WIP)
- Book
- Website (old)
Goals
- Implement web application for passgen (temporary, local, account-based, don't store master passphrase)
- Write documentation for passgen, including benchmarks and other data
- Implement quiz application for measuring the memorability of different kinds of passphrases (numeric, alphanumeric). Control for native language.
- Distribute on mturk, lobsters, hacker news
- Write paper for passgen (topic: todo)
Notes
- Incorporate https://seirdy.one/posts/2021/01/12/password-strength/
- Maybe add to KeePassXC/Mozilla?
Milestones
| Date | Description |
|---|---|
| 2024-09-14 | Rust version created as passgen-rs. |
| 2023-01-10 | Implemented and builds WASI version of passgen-c. |
| 2021-11-13 | Registered https://passgen.it and hosting documentation with mkdocs. |
| 2021-10-10 | Implemented dynamic wordlist loading and word-choosing. |
| 2019-10-06 | Implemented pronounceable word generation based on a markov-chain. |
| 2019-07-04 | Implemented pattern parsing. |
| 2012-04-06 | Initial passgen repository created as password generator with fixed patterns. |
diff.rs
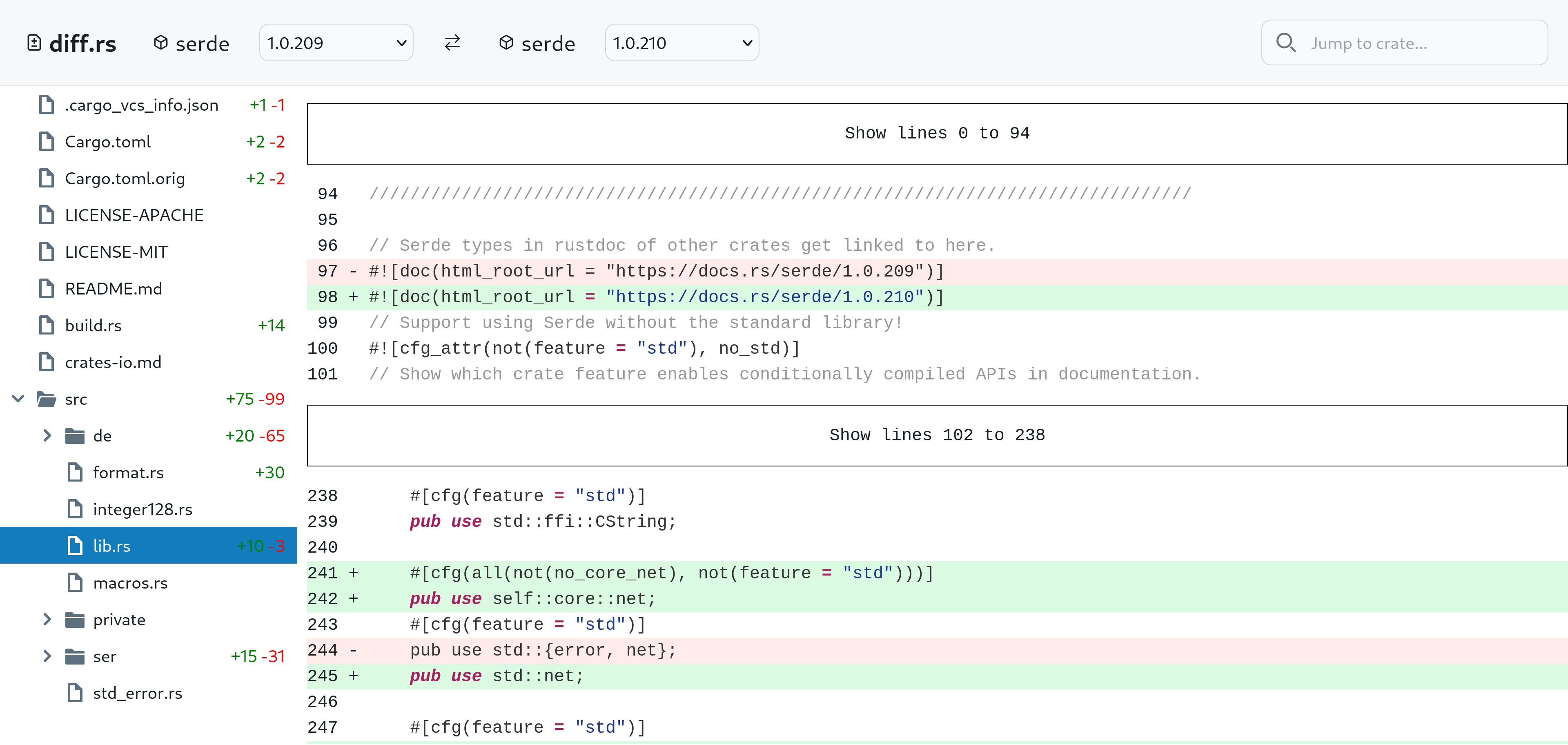
A web application which lets you visualize the differences between versions of Rust crates, to quickly see what changed. It is somewhat responsive and makes uses of caching to be quite fast.
It lives entirely in the browser: it has no backend. It is able to fetch a crate's source, uncompress and unpack it, and run a diff algorithm over it, all in the browser and in a split second. This is made possible thanks to Rust's support for WebAssembly. It can use Rust crates and they (mostly) just work.
This project was an exploration into the Rust frontend web development for me. I used it to explore the Yew framework, which lets you write Rust WebAssembly frontends using a React-like component model.
Links:
Architecture
Screenshots
Searching for a crate.
Viewing the differences between two crate versions.
Milestones
| Date | Description |
|---|---|
| 2024-09-18 | Syntax highlighting support (contributed by Nika) |
| 2024-04-02 | Verify hashes of crate sources |
| 2024-04-02 | Migrate to Tailwind CSS for layout and theme |
| 2023-03-17 | Fold unchanged lines (contributed by Raphael) |
| 2023-02-12 | First commit |
OpenVet
Idea:
- platform for collaboratively vetting rust crates
- simple design, based on sqlite
Features
-
Show raw crate sources
-
Ability to expand macros (click to expand?)
-
Ability to expand build scripts (or review manually?)
-
All changes tracked with a blockchain-like data structure:
- Crate changes (uploads, yanked, etc)
- Vetting/auditing changes (per-user?)
-
Idea: expose crate sources as Git repositories (https://git-scm.com/book/en/v2/Git-Internals-Transfer-Protocols)
Checks
- lib name matches crate name
- use of unsafe
- libraries it links with
- build script
- proc macro use
- use of FFI
- cargo vcs info works, commit exists
Articles
https://opensource.googleblog.com/2023/05/open-sourcing-our-rust-crate-audits.html
https://raw.githubusercontent.com/bholley/cargo-vet/main/registry.toml
https://github.com/crev-dev/cargo-crev
https://kerkour.com/rust-stdx
https://lib.rs/crates/bitflags/audit
Builds.rs
Web application to build and serve artifacts for all crates on crates.io. Focus is on automatic creation of binary builds for several platforms.
Technical
- Backend: Rust
- Frontend: Rust
- Domain: builds.rs
- Documentation: docs.builds.rs
- Repository: buildsrs/buildsrs
Milestones
- Repository created
- Basic project structure
CloudFS
Idea: cloud-native filesystem, in the spirit of local-first software.
- Works well with cloud services, such as object stores.
- Ability to snapshot, go back in time, similar to git.
- Uses content-addressed storage and some clever data structures.
- Ability to self-host storage, but use cloud proxy.
- Ability to lazy-load, to only fetch content you are interested in
- Ability to work offline.
Architecture

CloudFS consists of three components: it is a basic client/server architecture, where the server (which can be self-hosted, or hosted in the cloud) manages the state of the filesystem. It stores the metadata locally. The data itself can be stored in any key-value store and is immutable (due to it using content-addressed storage). Data storage can be partitioned or replicated easily.
Optionally, a relay can be used which is a cloud-hosted entity. This facilitates communication between the client and the server. It caches any blobs requested through it, so that access is possible even when the server is on a low-uplink connection. It also ensures the filesystem is readable when the server is down, as long as the chunks are cached.
Primitives
Blob store
Uses merkle-trees of data chunks.
Key-Value store
Uses G-trees storing hashes of blobs (merkle tree root hashes).
Implementation
Cells
Idea: build a spreadsheet application closely on top of a database.
- Every tab is just a table.
- You get filtering, aggregation and such for free.
- Columns have data types. Bonus points if data types can be dynamically defined using WebAssembly, which also containers methods to render them as HTML.
- Columns can also be defined as formulas (written in a declarative/functional way).
- You can further write scripts (typically in any language, for example Python). These need to be somewhat deterministic, and track what queries they perform to determine which input data they depend on.
- You can define things like graphs as queries of the data. They update in real-time as the data changes.
DigitalShed
Web application to track physical items using QR codes, intended to be used to track all the things inside a workshop (shed).
Technical
- Frontend: Rust
- Backend: Rust
- Domain: digitalshed.app
- Repository: xfbs/digitalshed
Ideas
- Represent every shed as a separate SQLite database, which is stored in S3 when not in use. When in use, a backend server is designated for it. It can be downloaded at any point.
- Allow for a registry-like experience when it comes to custom metadata types.
- Build an integration to make sheds locally searchable, so that you can borrow things from your neighbour. The app could offer some kind of insurance system whereby the risk to lenders is minimized.
Milestones
- Repository created
- Rough initial skeleton crated
HomeServer
Idea: caching server for offline-enabled working
Caches:
- Code
- GitHub
- GitLab
- Crates
- Apt/Rpm
- Information
- Wikipedia
- Web cache
- Media
- YouTube
- Spotify
SSH
Idea:
- Self-service tool for generating SSH certificates
Workflows
Initialisation
- Creates CA certificate
Client Certificates
- Sign-in with identity provider (Keyclock, for example)
- Upload of SSH public key
- Requires verification: signed message for tool
- Requires two-factor authentication: email with confirmation
- Request to generate certificate
- Certificate is valid for specified period (one month by default)
Certificate is create with:
-
principal: username (from identity provider)
-
comment: email address (from identity provider)
-
additional principals:
member-te-developers,member-te-sysadmins(one principal per group membership) -
more principals:
email-domain-example.com -
other metadata?
-
options restrictions?
-
All signing requests are logged, including inputs/outputs.
-
Signing can be done on external machine
Machine Certificate
- Upload of machine hostname pubkey
- Requires approval from other group members?
- Generates key (limited validity?)
- UI shows all machines and when they might expire, Extensions need to be performed manually (maybe with daemon on machine or by SSHing into it and updating host cert?)
Reading
Rustdoc2man
What if we could generate man pages from rustdoc output?
Restless
Restless is a (prototype) crate that allows you to define your REST API in Rust using the type system. Once you have defined it like this, Restless comes with support for various HTTP clients that you can use to make your API requests.
API clients it supports:
- Reqwest
- Gloo (for WASM web applications)
- Axum (mock API requests to test services)
With Restless, every API request is fully captured by a struct type. You
implement a specific trait for it, depending on the type of request. For example,
to implement a GET request, you implement the GetRequest type.
Example
Imagine you have an API that lets your users search. The query string is /search?q=<text>.
When you issue a search, the response is a JSON document that looks like this:
[
{
id: 2381912,
title: "10 tips they don't want you to know about"
}
]
To capture this API, you first write some Rust struct definitions to capture your request and the response you expect. Depending on how you use them,
#![allow(unused)] fn main() { #[derive(serde::Serialize)] struct SearchRequest { #[serde(rename = "q")] query: String, } #[derive(serde::Deserialize)] struct SearchResponseItem { id: u64, title: String, } }
Next, you implement the GetRequest with all the information that Restless needs to
issue your request and interpret the response.
#![allow(unused)] fn main() { use restless::{*, data::Json, query::Qs}; use std::borrow::Cow; impl GetRequest for SearchRequest { type Response = Json<Vec<SearchResponseItem>>; type Query = Qs<Self>; // query to use (?q=query) fn query(&self) -> Self::Query { self.clone() } // path to make request to (/search) fn path(&self) -> Cow<'_, str> { "search" } } }
With this done, you can now issue your request. Depending on the HTTP library you are using, this might work differently.
MacroDB
I like using databases to store things. Specifically, using SQLite is often nice, even for small, local applications. However, there are cases where you just want to store some relational data in-memory and have some indexes for it to look up values quickly.
This is where MacroDB comes it. It is a Rust macro that lets you define a database-like schema, and generates code for you to insert and delete rows. The code it generate fully handles updating all indices upon insertion, deletion and mutation of values.
It supports:
- Tables
- Primary keys
- Unique indexes
- Indexes
- Constraints
It is also generic over the underlying data structures you use to store primary
keys and indices. You can use HashMap or BTreeMap-backed data structures
for each.
Examples
Imagine you want to create a table to represent users. Every user has an ID, an email address and a name. The ID and the email should be unique per user. Users also have tags, and it should be able to look up all users with a given tag.
Conceptually, this means we need two tables: a table of users, and a table of user-tag associations. We have to define structs for each:
#![allow(unused)] fn main() { struct User { id: u64, email: String, name: String, } enum Tag { Admin, Supervisor, Employee, Guest, } struct UserTag { user: u64, tag: Tag, } }
Todo
Tupperware
Tupperware is an experiment in Rust that allows you to define structs
without specifying how the fields are stored. This allows you to build
generic structs that be adapted to specific use-cases, for example storing
certain fields wrapped in an Arc for cheap immutable cloning in multithreaded
environments, while using Rc for single-threaded scenarios.
Documentation for it is available here.
Examples
For example, if you want to define a User struct which stores a user name and
a list of groups the user is part of, but you want to be generic over what container
those fields are stored in, you could define it like this:
#![allow(unused)] fn main() { use tupperware::Storage; enum Group { Admin, Supervisor, User, } pub struct User<S: Storage> { name: S::Type<str>, groups: S::Type<[Group]>, } }
With this definition, you can now swap in different variants of Storage to specify how
the fields should be stored. Here is a few examples:
#![allow(unused)] fn main() { // this is what User<Inline> would look like pub struct User { name: String, groups: Vec<Group>, } // this is what User<Arc> would look like pub struct User { name: Arc<str>, groups: Arc<[Group]>, } }
Storage Containers
| Name | Description |
|---|---|
Arc | Stores anything in Arc<T> |
Rc | Stores anything in Rc<T> |
Box | Stores anything in Box<T> |
Inline | Stores anything inline. Stores str as String, [T] as Vec<T>, Path as PathBuf, OsStr as OsString. |
Ref<'a> | Stores anything as &'a T. |
Use-Cases
I mainly wrote this crate to see if it could be done. It may have some
applications when writing async code, and you want to make it easy to switch at
compile time between thread-safe variants of your code (using Arc) and
single-threaded variants (using Rc) by using this trait in places where you
have data you want to clone and share with different async spawn points.
It might be useful to you, or it could give you some inspiration.
tagged
Imstr
In Rust, you can cheaply get slices of string.
#![allow(unused)] fn main() { let string = String::from("Hello"); let slice = &string[0..1]; }
You can also use reference counting to cheaply copy strings around, for example when you use multi-threaded async applications.
#![allow(unused)] fn main() { let string = Arc::new(String::from("Hello")); let copy = string.clone(); }
However, when you create a slice of a string, it has a lifetime attached to it. This means that you cannot simply move this to another thread, as there is no guarantee that the string will continue existing (for example, if your current thread panics, it might be deallocated while the other thread is still accessing it).
Unfortunately, Rust has no built-in way to get an owned slice of an a string in an Arc
container.
This is where imstr comes in: it is an immutable string, that allows you to cheaply
create substrings from it. The substrings you create from it are still owned and can
be safely passed around to other threads.
You can find the documentation for imstr here.
mdBook Files
mdBook Docker Run
Pointer Identity
Serde Path
TraitScript
An idea for a scripting language that draws heavy inspiration from Rust. The idea is to take Rust's traits concept, but apply it to a dynamic language. Trait implementations for types then live as dynamic run-time information.
Bluewhale
What if you could model logic in Rust, using Rust's support for asynchronous execution? That is what the Bluewhale project is attempting to find out. It tries to build a framework for signal propagation, and implement primitives, which can then be used to build and simulate digital designs.
One of the questions that this project is trying to solve is that of speed: how good is the performance of a logic simulation written in Rust using the async ecosystem?
Some interesting possibilities that the async ecosystem enables is, for example, to be able to split the computational workload between multiple CPU cores. However, due to the communication overhead, this might not necessarily result in faster execution. Project Bluewhale could be used to get some data on this.
Cheetah
The Cheetah project attempts to implement an embedded database in Rust, similar to SQLite. However, it gets rid of the cruft of the 1980ies that our current databases are built on, and tries to reimagine data storage in a way that makes more sense.
Model Query Language
Instead of using SQL, which is a misdesign and leads to terrible code, it uses a modern query language that allows for modern concepts.
table("user_names").filter(|u| u.name = "Patrick")
Assertions
It has support for writing assertions right into the schema. These can be used for unit testing or for ensuring that data stays consistent, even if the code accessing it has bugs.
assert(table("user_names").all(|u| u.birthday < date::now())
Extensible
It has support for loading plugins of various kinds. These are distributed as WebAssembly components. Plugins can expose data types, utility functions, even macros.
let uuid = import("uuid", "^0.5.0")
table("users", {
"name": string,
"id": uuid::uuid,
})
Macros
Macros can be used at any point to automatically apply operations.
let auto_deleted_at = import("auto_deleted_at", "^0.5.1")
table("users", auto_deleted_at!({
"name": string,
"birthday": date,
}))
This works because the system uses code-is-data, where even type definitions for structs are simply structs themselves.
Something similar to Zig's MultiArrayList should be supported to turn a table from row-based into column-based.
- https://andreashohmann.com/zig-struct-of-arrays/
- https://github.com/ziglang/zig/blob/master/lib/std/multi_array_list.zig
It should also be possible to use some macro to turn a field of a type into an external table (maybe because it is very large or because it changes often).
Another consideration: separating logical structs from how they are stored (for example, arrays can be stored inline or in a sub-table).
Table Namespacing
Should tables be accessible via some kind of globals?
$user_accounts.filter(|row| row.name == "myname")
Or should they be accessible via some functions?
table("user_accounts").filter(|row| row.name == "myname")
Functional
The query language is strictly functional. This allows for easily defining derived fields.
table("users", {
"id": uuid,
"name": string,
"orders": query(|u| count(table("orders").filter(|o| o.user = u.id)))
})
It also means that you can define methods on tables and rows easily.
Migrations
Migrations are a concept that is built-in to the database. The database has support for running them.
transaction(|| {
table("users").column("id").upgrade(import("uuid", "0.6.0"))
})
Can we handle data transformations? How do we implement upgrading?
Custom Encoding
Rows can use custom encoding schemes, dynamically defined using WebAssembly. This allows for storing raw blobs of encoded data, but still being able to define indices on them.
Query AST
Queries make use of an AST, allowing them to run in parallel (if required).
It should be able to run on a current_thread runtime, or on thread-per-core
architecture.
Queries should be able to have a budget and priority attached.
The reason for doing AST queries is that it allows for parallelisation.
Reading
A Critique of Modern SQL And A Proposal Towards A Simple and Expressive Query Language
SQL Has Problems. We Can Fix Them: Pipe Syntax in SQL
https://howqueryengineswork.com/
https://transactional.blog/how-to-learn/disk-io
https://dl.acm.org/doi/abs/10.1145/3534056.3534945
https://xnvme.io/
Rust Project Primer
TechRef
- Reference page for technical topics